
はじめに
今回は第4章の後半を解いていきたいと思います.
第4章の後半では,実際に文章中に単語がどの程度含まれているかを確認していきます.
単語の出現頻度などはその文章のジャンルを表す重要な特徴として自然言語処理の中でも使われることがあります.これを機にどのように抽出するのかを学んでいきましょう.
また,4章の前半で作成したマッピング型のリスト,”sentence_blocks”を後半でも使っていきますのでご注意ください.
35. 単語の出現頻度
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
import collections
word_list = []
for sentence_block in sentence_blocks:
for block in sentence_block:
if block["pos"] == "記号":
continue
word_list.append(block["base"])
word_count = collections.Counter(word_list)
print(word_count.most_common()[:10])#出力
[('の', 9194), ('て', 6848), ('は', 6420), ('に', 6243), ('を', 6071), ('だ', 5972), ('と', 5508), ('が', 5337), ('た', 4267), ('する', 3657)]解説
標準ライブラリcollectionsのCounterクラスを使うことでリスト内に出てきた各要素出現回数を取得することができます.
これを知っていれば,出現する単語をリストに保存していき,最後にmost_common()で出現頻度が多い順に要素を取得すれば問題を解くことができます.
collections.Counter()後は標準で要素の多い順になっています.
また,出力がcounterオブジェクト型になっているので,出力結果を利用する際には注意してください.
36. 頻度上位10語
出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
コマンド
!pip install japanize-matplotlib
import matplotlib.pyplot as plt
import japanize_matplotlib
top10_word, count = zip(*word_count.most_common()[:10])
plt.bar(top10_word,count)
出力
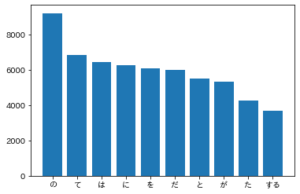
解説
matplotlibを用いて35問目で作成した頻出単語のリストを表示するだけですね.
Colab環境でmatplotlibの日本語の表示がうまくできない場合は,”japanize-matplotlib”をインストールすることで表示できるようになると思います.
37. 「猫」と共起頻度の高い上位10語
「猫」とよく共起する(共起頻度が高い)10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
コマンド
import collections
import matplotlib.pyplot as plt
import japanize_matplotlib
with_cat_list = []
for sentence_block in sentence_blocks:
# word_list = [block["base"] for block in sentence_block if block["pos"] != "記号"]
#意味のありそうな名詞,動詞,形容詞に絞ったver
word_list = [block["base"] for block in sentence_block if block["pos"] in ["名詞","動詞","形容詞"]]
if "猫" in word_list:
#複数回猫が出てくる場合や"*"の記号に対応するためリスト内包表記で作成
word_list = [word for word in word_list if word not in ["猫","*"]]
with_cat_list += word_list
with_cat_count = collections.Counter(with_cat_list)
print(with_cat_count.most_common()[:10])
top10_word, count = zip(*with_cat_count.most_common()[:10])
plt.bar(top10_word,count)
出力
#出力
[('する', 144), ('事', 59), ('吾輩', 58), ('いる', 58), ('ある', 55), ('の', 55), ('人間', 40), ('ない', 39), ('云う', 38), ('もの', 36)]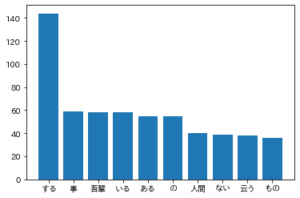
解説
下35,36問の復習ですね.
今回は猫と一緒にどんな名詞や形容詞,動詞が出現しているかを調べる形にコードを変えてみました.
”吾輩は猫である”のタイトル通り,”吾輩”や”ある”が共起する単語として出ていることがわかりました.
38. ヒストグラム
単語の出現頻度のヒストグラムを描け.ただし,横軸は出現頻度を表し,1から単語の出現頻度の最大値までの線形目盛とする.縦軸はx軸で示される出現頻度となった単語の異なり数(種類数)である.
コマンド
import collections
import matplotlib.pyplot as plt
word_list = []
for sentence_block in sentence_blocks:
for block in sentence_block:
if block["pos"] == "記号":
continue
word_list.append(block["base"])
word_count = collections.Counter(word_list)
word, count = zip(*word_count.most_common())
# ヒストグラムを出力
plt.hist(count,bins=50)
plt.show()
出力

解説
ヒストグラムの描き方を知っていれば難なく解ける問題でしたね.
binsで指定した範囲毎に含まれている要素の個数をヒストグラムに出力してくれます.
今回の場合,50で設定しているので最小値から最大値までのカウントを50分割してくれています.
基本的に文章中でたまにしかでない単語で構成されているということがこのグラフからわかりますね.
39. Zipfの法則
単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
コマンド
import collections
import matplotlib.pyplot as plt
word_list = []
for sentence_block in sentence_blocks:
for block in sentence_block:
if block["pos"] == "記号":
continue
word_list.append(block["base"])
word_count = collections.Counter(word_list)
word, count = zip(*word_count.most_common())
rank = [i+1 for i in range(len(word))]
plt.plot(rank, count)
#scaleをlogに変換
plt.yscale('log')
plt.xscale('log')
plt.xlabel('ranking',fontsize=18)
plt.ylabel('count',fontsize=18)
# グリッドの表示。
plt.grid(which="both")
plt.show()
出力

解説
本問題は図の両軸をlogスケール変換することで問題を解くことができます.
zipfの法則とは下記のようなものを指すようです.
確かに,出現頻度の順位が落ちていくと反比例的に出現回数も減少していることが図から見て取れますね.
大量のテキストに使用された語句の頻出順位と頻度を集計すると、頻出順位がk番目の頻度は頻出順位1番目の頻度を1/kした値になる法則をジップの法則(ゼータ分布)という。
最後に
今回は第4章の後半の問題を解いてきました.
形態素解析した結果の活用方法や可視的に出現頻度を把握するということを実施してきました.
「猫」と共起する単語を調べることをしましたが,他の単語でも同様のことをやって見るとまた違った傾向が見て取れると思うので色々と試してみてください.
次回は,第5章の前半を解いていきます.
次の記事
前の記事


コメント