
はじめに
最近は新しいAIがどんどん出てきて面白い世の中になってきていますね!
今回は先日公開されたMetaのSAM(Segment Anything Model)のデモを今回は触ってみたのでその紹介をしたいと思います.
デモの中では画像からオブジェクトを識別し,そのオブジェクトを切り出すことができます.
SAM(Segment Anything Model )とは
SAMは,SA-1B データセット(1Bの画像マスクと11Mの画像を持つ)で学習された画像内のオブジェクトをセグメント化するモデルです.
モデルの特徴としては,大規模なデータセットによって一般的な概念を学習しているため,データセットにない画像でもゼロショットでセグメントが可能という所にあります.
これを使えば簡単に画像から人や動物のみを切り出したりすることができます.
SAMモデルは,下記のように特徴的な学習方法によって高精度なモデルを作成しています.
- 大規模なデータセットの構築
11Mの画像データと1Bのマスクで構成されたSA-1Bデータセットを利用 - 画像に対して三つの形式(ポイント,ボックス,マスク)でセグメントを実施し,正解データと比較する事前学習
- モデルの予測結果としては上記のセグメント方法に対して,複数のマスクと信頼スコアを生成
下記の図のようなフローで画像に対して複数のマスクとスコアを出力
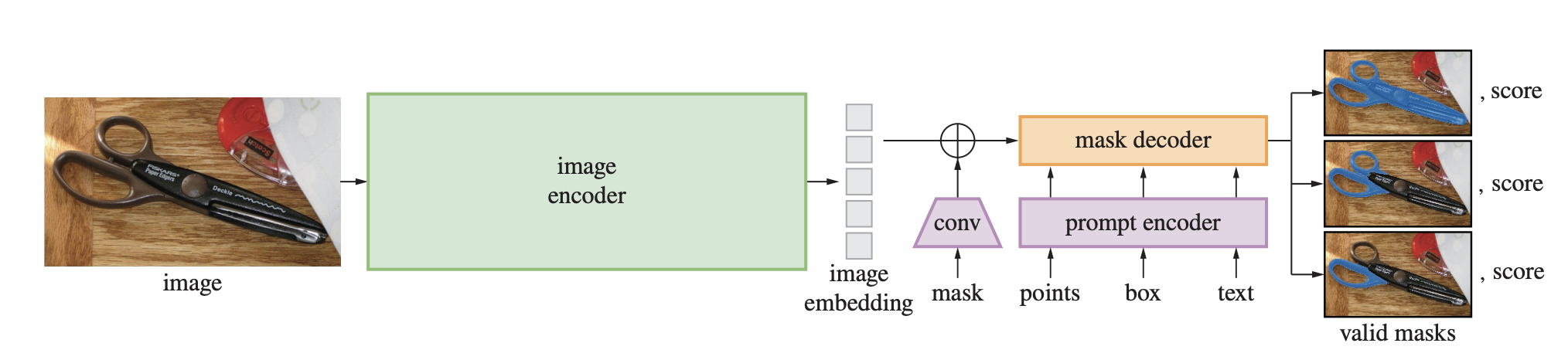
モデルのより細かい構造や中身,他のモデルとの比較等に関しては論文を参照してください.
デモを触ってみた
では,本題のデモを触っていきたいと思います.
デモのページはこちらになります.
まずは,セグメントとして抽出したい画像を選択します.
選択すると下記のような画面に飛びます.
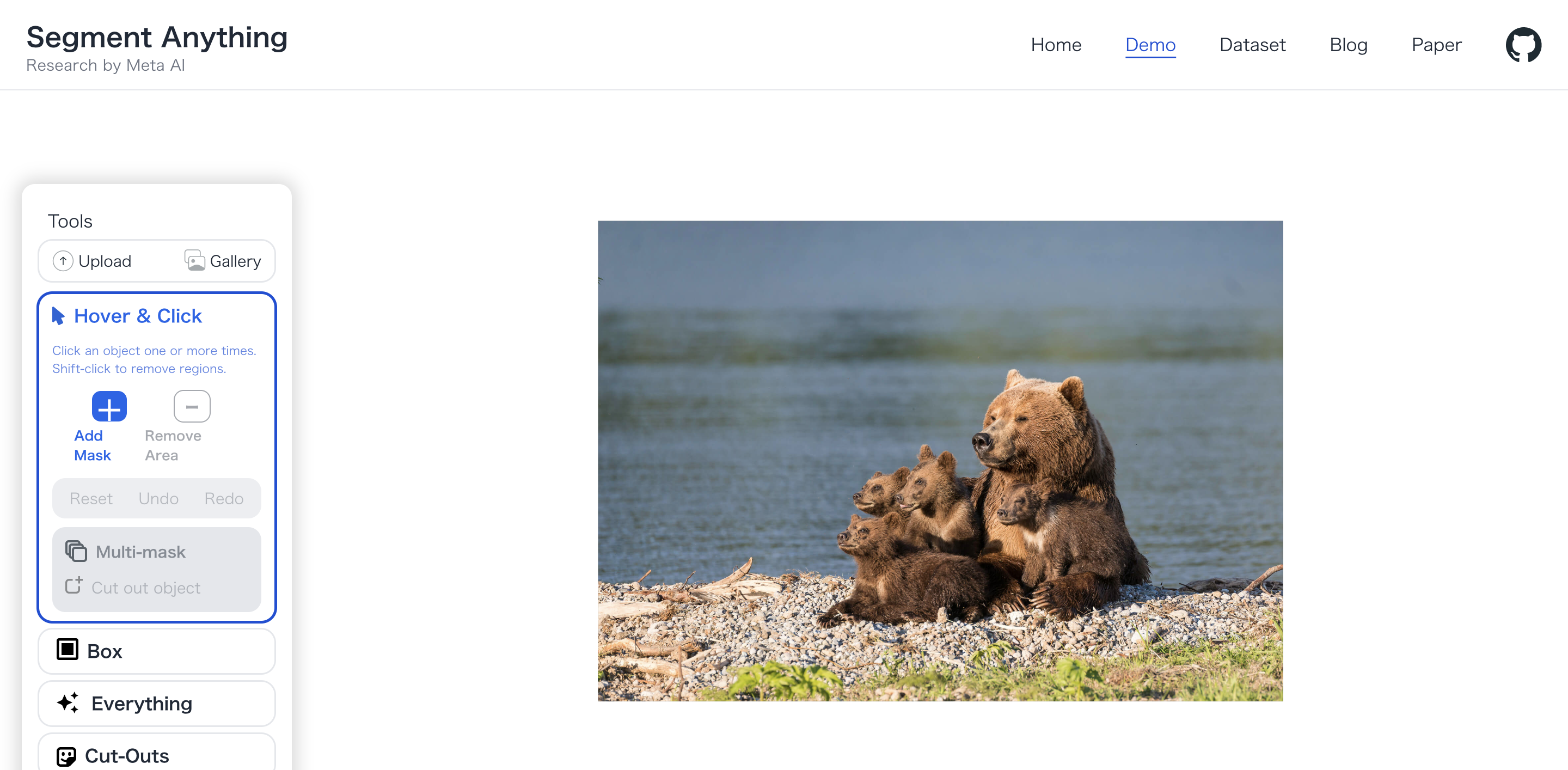
セグメントとして切り出したい部分をクリックすることで,オブジェクトの範囲を自動で認識してくれます.また,細かい調整をしたい場合はさらにクリックして領域を増やしたり,「RemoveArea」を選択した状態で削除したい部分をクリックすることで対象のセグメント範囲を狭めることができます.
下記が利用のイメージになります.
まず,「Hover&Click」機能の利用イメージです.
次に,「Everything」の利用イメージです.
上記のEverythingの機能を使うと,モデルが内部的に画像を細かくセグメントに分けられていることが見て取れますね.
このモデルを使うことで,自分で撮った画像から必要な部分を切り出して背景透過することなどが簡単にできるようになりそうです.
流行りの画像生成AIによって切り出したセグメントに対して新たな背景をつけてみることや,背景だけ切り出してオブジェクトを生成することなどにも使えそうです.
次回は画像生成にもチャレンジしてみようと思います.


コメント