
はじめに
今回は第5章の前半を解いていきたいと思います.
第5章では,文章を係り受け解析し,文章の構造を理解するための章になっています.
文章の解析にはWikipediaのAIに関するテキストを抜き出したファイルを用いており,係り受け解析にはCaboChaを使っています.
前準備
まずは,GoogleColaboratoryにCabochaを入れ,ai.jaファイルの係り受け解析の結果を取得したいと思います.
#ai.jaテキストのダウンロードと解凍
!wget https://nlp100.github.io/data/ai.ja.zip
!unzip ai.ja.zip
#Mecabのインストール
!apt install mecab libmecab-dev mecab-ipadic-utf8
#CRF++のインストール
import os
filename_crfpp = 'crfpp.tar.gz'
!wget "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7QVR6VXJ5dWExSTQ" \
-O $filename_crfpp
!tar zxvf $filename_crfpp
%cd CRF++-0.58
!./configure
!make
!make install
%cd ..
os.environ['LD_LIBRARY_PATH'] += ':/usr/local/lib'
#CaboChaのインストール
FILE_ID = "0B4y35FiV1wh7SDd1Q1dUQkZQaUU"
FILE_NAME = "cabocha.tar.bz2"
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=\
$(wget --quiet --save-cookies /tmp/cookies.txt \
--keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=$FILE_ID' -O- \
| sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=$FILE_ID" -O $FILE_NAME && rm -rf /tmp/cookies.txt
!tar -xvf cabocha.tar.bz2
%cd cabocha-0.69
!./configure --with-mecab-config=`which mecab-config` --with-charset=UTF8
!make
!make check
!make install
%cd ..
!cabocha --version
#係り受け解析
%cd /content
!cat ai.ja.txt | cabocha -f1 > ai.ja.txt.parsed
!head -10 ./ai.ja.txt.parsed* 0 -1D 1/1 0.000000
人工 名詞,一般,*,*,*,*,人工,ジンコウ,ジンコー
知能 名詞,一般,*,*,*,*,知能,チノウ,チノー
EOS
EOS
* 0 17D 1/1 0.388993
人工 名詞,一般,*,*,*,*,人工,ジンコウ,ジンコー
知能 名詞,一般,*,*,*,*,知能,チノウ,チノー
* 1 17D 2/3 0.613549
( 記号,括弧開,*,*,*,*,(,(,(出力結果の確認方法に関してです.
1行目に関して
| * | 文節の開始位置 |
| 0 | 自身の文節番号 |
| -1D | 係り先番号(係先がない場合-1) |
| 1/1 | 主辞の形態素/機能語の形態素 |
| 0.000000 | 係りやすさの度合 |
これで問題を解く準備ができたので,第5章の問題を解いていきたいと思います.
40. 係り受け解析結果の読み込み(形態素)
形態素を表すクラスMorphを実装せよ.このクラスは表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をメンバ変数に持つこととする.さらに,係り受け解析の結果(ai.ja.txt.parsed)を読み込み,各文をMorphオブジェクトのリストとして表現し,冒頭の説明文の形態素列を表示せよ.
コマンド
class Morph:
def __init__(self, morph):
surface,attr = morph.split("\t")
attr = attr.split(",")
self.surface = surface
self.base = attr[6]
self.pos = attr[0]
self.pos1 = attr[1]
with open("ai.ja.txt.parsed", "r") as f:
blocks = f.read().split("EOS\n")
sentence_morphs = []
morphs = []
for block in blocks:
block = block.split("\n")
if block[0] == "" or len(block) ==0:
continue
for m in block:
if m =="" or m[0]=="*":
continue
morphs.append(Morph(m))
sentence_morphs.append(morphs)
morphs = []
for i in sentence_morphs[1]:
print(vars(i))
出力
{'surface': '人工', 'base': '人工', 'pos': '名詞', 'pos1': '一般'}
{'surface': '知能', 'base': '知能', 'pos': '名詞', 'pos1': '一般'}
{'surface': '(', 'base': '(', 'pos': '記号', 'pos1': '括弧開'}
{'surface': 'じん', 'base': 'じん', 'pos': '名詞', 'pos1': '一般'}
{'surface': 'こうち', 'base': 'こうち', 'pos': '名詞', 'pos1': '一般'}
{'surface': 'のう', 'base': 'のう', 'pos': '助詞', 'pos1': '終助詞'}
・・・
解説
まずは,文章の区切り毎にデータをblocksに読み込みます.
blocksを1行ずつ読み込み値が入っていない場合やアスタリスクで始まっている行をスキップし,目的の形態素を含むblockだけを取得します.このblockをMorphオブジェクトに格納していきます.
blockをタブ区切りすると最初の要素は表層系になります.残った要素に関してはカンマ区切りにすると6番目の要素が基本形,0番目の要素が品詞,1番目の要素が品詞詳分類1となります.
41. 係り受け解析結果の読み込み(文節・係り受け)
40に加えて,文節を表すクラスChunkを実装せよ.このクラスは形態素(Morphオブジェクト)のリスト(morphs),係り先文節インデックス番号(dst),係り元文節インデックス番号のリスト(srcs)をメンバ変数に持つこととする.さらに,入力テキストの係り受け解析結果を読み込み,1文をChunkオブジェクトのリストとして表現し,冒頭の説明文の文節の文字列と係り先を表示せよ.本章の残りの問題では,ここで作ったプログラムを活用せよ.
コマンド
#Morphオブジェクトの作成
class Morph:
def __init__(self, morph):
surface,attr = morph.split("\t")
attr = attr.split(",")
self.surface = surface
self.base = attr[6]
self.pos = attr[0]
self.pos1 = attr[1]
#Chunkオブジェクトの作成
class Chunk:
def __init__(self, morphs, dst):
self.morphs = morphs
self.dst = dst
self.srcs = []
sentence_chunk = []
chunk_list = []
morphs = []
for s in blocks:
block = s.split("\n")
if block[0] == "" or len(block) ==0:
continue
for b in block:
if b =="":
continue
#blockの先頭が*の時,係り受けの内容が記述
elif b[0] == "*":
if len(morphs) > 0:
chunk_list.append(Chunk(morphs,dst))
#chunk_id, 係り先の番号, 主辞(文節の中心となる単語)/機能語(助詞など)の位置, Score
dep = b.split(" ")
dst = dep[2][:-1]
morphs = []
continue
morphs.append(Morph(b))
chunk_list.append(Chunk(morphs, dst))
#一文分のChunkに対して係り元の文節を追加
for i, c in enumerate(chunk_list):
if c.dst != "-1":
chunk_list[int(c.dst)].srcs.append(i)
sentence_chunk.append(chunk_list)
chunk_list = []
morphs = []
for c in sentence_chunk[1]:
print([m.surface for m in c.morphs], c.dst, c.srcs)
出力
['人工', '知能'] 17 []
['(', 'じん', 'こうち', 'のう', '、', '、'] 17 []
['AI'] 3 []
['〈', 'エーアイ', '〉', ')', 'と', 'は', '、'] 17 [2]
['「', '『', '計算'] 5 []
['(', ')', '』', 'という'] 9 [4]
['概念', 'と'] 9 []
・・・
解説
先ほどの形態素(Morph)オブジェクト加えて,係り先,係り元を格納したChunkオブジェクトを作成し,それを文節毎に保持するという問題です.
まずは,40で作成したblocksを再度読み込みます.
アスタリスクを含む行がきた場合,文節の持つ,自身の文節番号と係り先番号の情報があるため.それを抽出します.それ以外の行の場合,形態素に関しての行になるので40と同様にMorphオブジェクトに形態素を格納していきます.文節毎にMorphオブジェクトをまとめ,Morphオブジェクトのリストを含むChunkリストを作成します.作成したChunkオブジェクトにまだ係り元が含まれていないので,Chunkオブジェクトの係り先に対して自分の文節番号を係り元リストに追加するような処理を最後に実施しています.
42. 係り元と係り先の文節の表示
係り元の文節と係り先の文節のテキストをタブ区切り形式ですべて抽出せよ.
ただし,句読点などの記号は出力しないようにせよ.
コマンド
#抽出対象の文章のリスト番号を指定
n = 1
for c in sentence_chunk[n]:
print("".join([m.surface if m.pos != '記号' else '' for m in c.morphs])+"\t"+
"".join([m.surface if m.pos != '記号' else '' for m in sentence_chunk[n][int(c.dst)].morphs]))
出力
人工知能 語
じんこうちのう 語
AI エーアイとは
エーアイとは 語
計算 という
という 道具を
概念と 道具を
・・・
解説
リスト内包表記を用いているので少々コードが読みづらいですが,40.41で作成したMorphオブジェクトとChunkオブジェクトから必要な要素を抽出しているだけです.
各文節を表すChunkオブジェクトのリストに対してそのChunkオブジェクトの要素に含まれているMorphオブジェクトの表層系を抽出します.この時に,記号を抽出しないように品詞が記号の場合を避けるようにします.
次に,Morphオブジェクトを抽出した文節の係り先に対して同様の処理を実施することで目的の結果を受け取ることができます.
43. 名詞を含む文節が動詞を含む文節に係るものを抽出
名詞を含む文節が,動詞を含む文節に係るとき,これらをタブ区切り形式で抽出せよ.
ただし,句読点などの記号は出力しないようにせよ.
コマンド
#抽出対象の文章のリスト番号を指定
n = 1
for c in sentence_chunk[n]:
src_phrase_surface = [m.surface if m.pos != '記号' else '' for m in c.morphs]
src_phrase_pos = [m.pos if m.pos != '記号' else '' for m in c.morphs]
dst_phrase_surface = [m.surface if m.pos != '記号' else '' for m in sentence_chunk[n][int(c.dst)].morphs]
dst_phrase_pos = [m.pos if m.pos != '記号' else '' for m in sentence_chunk[n][int(c.dst)].morphs]
if "名詞" in src_phrase_pos and "動詞" in dst_phrase_pos:
print("".join(src_phrase_surface)+"\t"+"".join(dst_phrase_surface))
出力
道具を 用いて
知能を 研究する
一分野を 指す
知的行動を 代わって
人間に 代わって
コンピューターに 行わせる
研究分野とも される
・・・
解説
42の問題の応用ですね.先ほど同様に対象の文節の表層系と係り先文節の表層系を抽出します.同様の形式でMorphオブジェクトに格納されている品詞の情報も抽出します.抽出した品詞情報の中に対象の文節であれば品詞リストの中に名詞が含まれていれば,係り先の文節に関しては品詞リストの中に動詞が含まれていれば,結果を出力するという形で実装することができます.
ここまで出力するとその文章の中で何が表現されていたか大体わかるようになりますね.
44. 係り受け木の可視化
与えられた文の係り受け木を有向グラフとして可視化せよ.
可視化には,Graphviz等を用いるとよい
まずは,準備としてgraphvizの出力結果を受け取った時に日本語で表示できるようにfontをインストールします.
!apt-get -y install fonts-ipafont-gothic次に係り受け木を可視化していきます.
コマンド
import graphviz
#Graphvizのオブジェクトを作成
g = graphviz.Graph(format='png', filename='dependency')
g.attr('node', fontname='IPAGothic')
n = 1
for c in sentence_chunk[n]:
src_phrase_surface = [m.surface if m.pos != '記号' else '' for m in c.morphs]
g.node("".join(src_phrase_surface))
for c in sentence_chunk[n]:
src_phrase_surface = [m.surface if m.pos != '記号' else '' for m in c.morphs]
dst_phrase_surface = [m.surface if m.pos != '記号' else '' for m in sentence_chunk[n][int(c.dst)].morphs]
g.edge("".join(src_phrase_surface), "".join(dst_phrase_surface))
# 保存
g.view()
コードを実行すると,dependency.pngというファイルが出来上がっているかと思います.
そちらをローカルに落として確認すると,下記のような画像が表示されると思います.
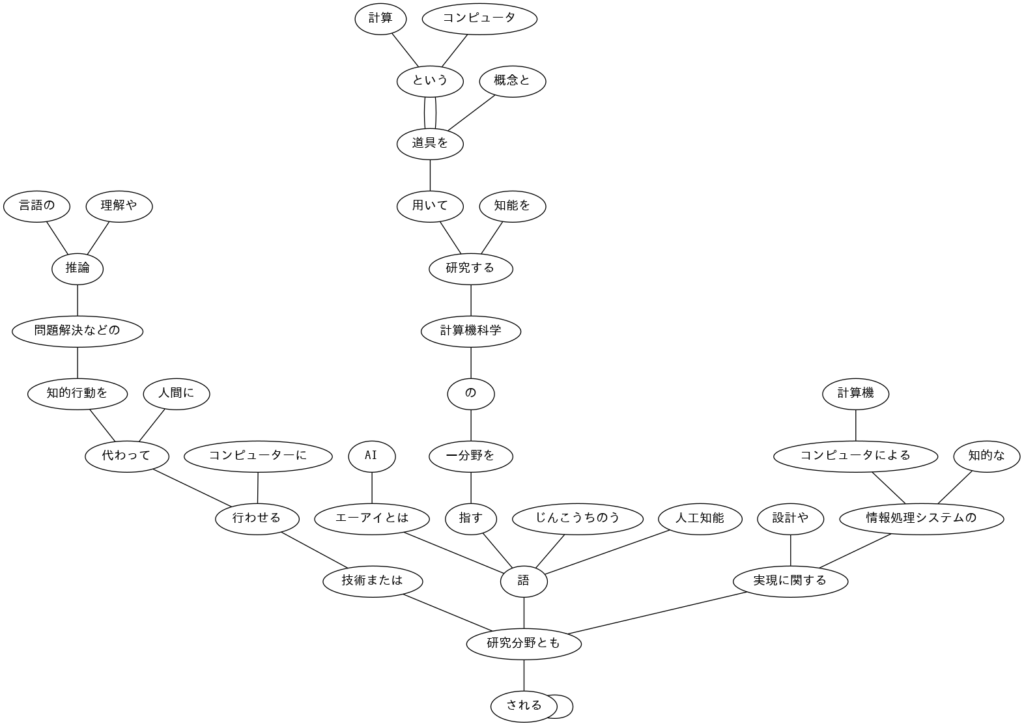
解説
まず初めに,文章全体の文節を全てGraphvizのノードに書き出します.
書き出したノードに対して係り先と係り元をGraphvizのedgeで結びつけます.
作成したグラフを最後に保存すれば係り受け木の完成です.
最後に
今回は第5章の前半の問題を解いていきました.
係り受け解析した結果を分析することで,文章の骨格となる部分を確認することができたり,文章の構成がどうなっているかを理解することができます.
一方で,問題を解くのに時間がかかり,これぐらいの確認なら人目で見てもいいかなと思ってしまいますね。。。
次回は,第5章の後半を解いていきます.
次の記事
- 【言語処理100本ノック解いてみた】 第5章後半(整備中)
前の記事


コメント