
はじめに
今回はGoogleColaboratoryでStable Diffusionを触ってみました.
StableDiffusionはStability.aiが提供している画像生成AIモデルになります.
StableDiffusionのモデルの中身に関してはこちらでわかりやすく解説してくれています.
本ブログでもその触りの部分を簡単に解説したいと思います.
Stable Diffusionとは
Stable Diffusionは拡散モデルに基づいて作られたモデルになります.
拡散モデルとは,ノイズを乗せた画像を入力とし,ノイズが乗る前の状態の画像を復元するように学習し,復元した画像と元の画像の差分を損失関数に持つようなモデルのことです.
下記がモデルの学習イメージになります.
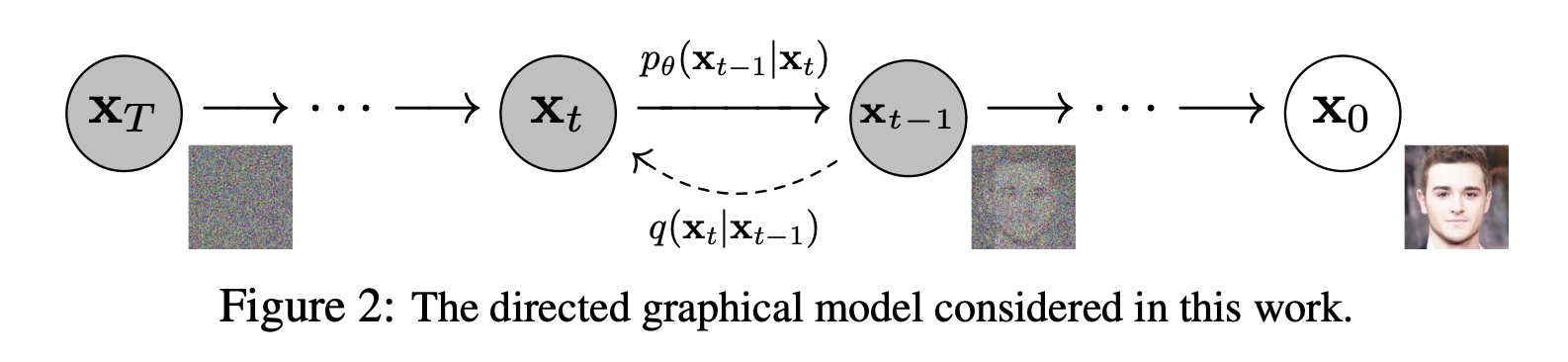
ノイズ画像 XTから元画像X0を復元させるステップを何回も繰り返し徐々にノイズを除去していくことによって画像を生成します。
具体的には、元画像X0にノイズを乗せる関数qをT回適用し、ノイズ画像XTを生成します。これは、ガウシアン (正規分布) に従うデータを生成して足し算すれば良いだけなので、人為的に簡単に生成することができます。この過程を、前向き過程 (forward process)、もしくは拡散過程 (diffusion process) といいます。
ステート・オブ・AIガイドの解説
このモデルのままではモデルの学習に時間が掛かってしまうという課題がありました.
そこで,Stable Diffusionで導入されたのがLDMと呼ばれるモデルになります.
LDMでは,画像を低次元の潜在空間に変換し,その低次元の潜在空間内で拡散モデルを適用します.低次元の空間で拡散モデルを利用することで学習にかかる時間を削減しながらも画像の特徴を理解し,そこから元の画像に戻すという二段階のプロセスを踏んで画像を生成します.
上記のモデルを元として,テキストと画像の類似度を測るCLIPというモデルを組み込んだものがStable Diffusionとされています.CLIPでは,画像とテキストを同じベクトル空間変換した上で学習を進めます.具体的な学習方法は下記のイメージになります.
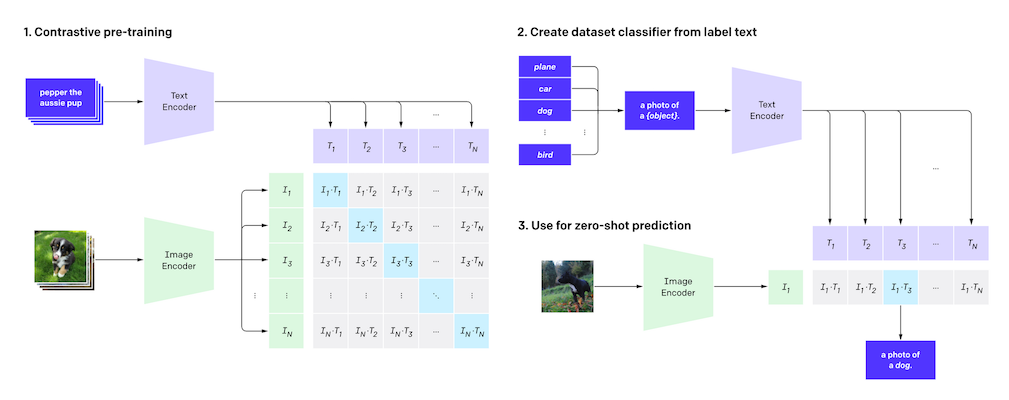 上記のContrastive pre-trainingでは,inputとなる文章から複数の候補の画像から正解の画像を予測するように学習をしています.
上記のContrastive pre-trainingでは,inputとなる文章から複数の候補の画像から正解の画像を予測するように学習をしています.
ここまでに挙げたようなモデルの仕組みを組み合わせることでテキストから画像を生成するStable Diffusionを実現されています.
では,実際にモデルを触っていきたいと思います.
モデルはこちらを参考に利用しています.
前準備
google colabratoryでは,ランタイムのタイプをGPUに設定してください.
また,Img2Imgで用いる画像を”input.png”としてアップロードしておいてください.
上記を実施した上で,まずは,必要なライブラリを環境にインストールします.
!pip install diffusers transformers accelerate scipy safetensors 前準備は以上です.
Text2Img
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
import torch
model_id = "stabilityai/stable-diffusion-2-1"
# Use the DPMSolverMultistepScheduler (DPM-Solver++) scheduler here instead
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")上記のコードを実行することで下記のような画像が生成できます.

ちょっとコード書いただけでこんなに簡単に画像が生成できるなんて…面白い時代ですね…
上記のコードのschedulerはDPMSolverMultistepSchedulerの他にも多数あり,こちらを変えることで,生成される画像の傾向が多少変わるようです.
また,推論のステップ数に関してはコードのimage = pipe(prompt).images[0]のpipe関数の引数num_inference_stepsでコントロールすることができます.
デフォルトではstep数50となっています.
利用しているschedulerでは20ステップ程度で高精度の画像が生成できるようです.
試しに,step数10とstep数100の画像を生成してみました.
 大まかな作りとしてはどちらも問題ないですが,step数10の方は馬の形が若干歪ですね.
大まかな作りとしてはどちらも問題ないですが,step数10の方は馬の形が若干歪ですね.
また,step数が大きい方が画像の細かさが上がっているようにみられます.馬の毛並みや宇宙服の表現の細かさが向上したように思います.
Img2Img
次に,img2imgを試してみたいと思います.
今回は自分のアイコンとして利用している狐の画像を元にimg2imgをしてみます.
まずは,img2imgを実行するためのパイプラインを準備します.
import torch
from diffusers import StableDiffusionImg2ImgPipeline
# StableDiffusionImg2Imgパイプラインの準備
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
model_id,
revision="fp16",
torch_dtype=torch.float16,
).to("cuda")
次に,入力画像とpromptを用意し,img2imgを実行します.
今回は入力画像をアニメ風に変えてもらうようにpromptを記述してみました.
# 画像生成
init_image = Image.open("input.png").convert("RGB")
init_image = init_image.resize((768, 512))
prompt = "change the image into anime style"
with autocast("cuda"):
images = pipe(
prompt=prompt,
image=init_image,
strength=0.35,
guidance_scale=8,
num_inference_steps=100,
).images
images[0].save("output.png")
下記が入力画像と出力画像の比較になります.
指示通り,イラスト風の画像に変換してくれています.

正直,今回の出力画像に関しては納得いくものができるまで,promptやstrength,num_inference_stepsを微調整しながら作成しました.
また,入力画像も元々の画像よりも画質が落ちるため,うまく特徴を把握できなくなってしまうのかもしれません.
終わりに
今回は,StableDiffusionを使って画像生成と画像変換を試してみました.
GoogleColabで簡単に実装できるので皆さんも試してみてください.
また,今後背景を変えることや画像の一部を変えることなどもしてみたいので,第二回,三回も記事を書いていきたいと思います.


コメント